たつをの ChangeLog : 2008-09-07
特殊な生態系の島「ソコトラ島」
2008-09-07-1
[Geography]
イエメンにある島、ソコトラ。
アラビア半島とソマリア半島の間。
ソトコト島ではありません。ソコトラ島です。
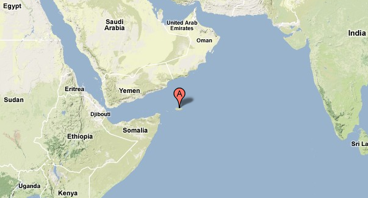
変な植物とかがいっぱいあるそうな。おもしろい!

- 地球上でもっとも地球に見えない島、ソコトラ島 (ぱるぷんてにゅーす)
http://lllparopuntelll.blog118.fc2.com/blog-entry-502.html
(注意:記事中にある城塞都市はソコトラ島ではありません)
- The Most Alien-Looking Place on Earth (Dark Roasted Blend)
http://www.darkroastedblend.com/2008/09/most-alien-looking-place-on-earth.html
(元ネタ)
ソコトラ島自体の詳細情報は英語版 Wikipedia で:
- Socotra - Wikipedia, the free encyclopedia
http://en.wikipedia.org/wiki/Socotra
あまり情報ないけど日本語版 Wikipedia:
- Wikipedia:ソコトラ島
アラビア半島とソマリア半島の間。
ソトコト島ではありません。ソコトラ島です。
変な植物とかがいっぱいあるそうな。おもしろい!
- 地球上でもっとも地球に見えない島、ソコトラ島 (ぱるぷんてにゅーす)
http://lllparopuntelll.blog118.fc2.com/blog-entry-502.html
(注意:記事中にある城塞都市はソコトラ島ではありません)
- The Most Alien-Looking Place on Earth (Dark Roasted Blend)
http://www.darkroastedblend.com/2008/09/most-alien-looking-place-on-earth.html
(元ネタ)
ソコトラ島自体の詳細情報は英語版 Wikipedia で:
- Socotra - Wikipedia, the free encyclopedia
http://en.wikipedia.org/wiki/Socotra
あまり情報ないけど日本語版 Wikipedia:
- Wikipedia:ソコトラ島
「Introduction to Information Retrieval」輪講第13回
2008-09-07-2
[IIR]
「Introduction to Information Retrieval」の輪講の第13回です。
- Introduction to Information Retrieval
http://www-csli.stanford.edu/~hinrich/information-retrieval-book.html
今回は六本木ヒルズの Baidu の会議室を使わせて頂きました。
ありがとうございました。百度!百度!

最初に恒例の「前章の復習 by id:naoya」
(http://d.hatena.ne.jp/naoya/20080907/1220796559)。
前章の確率ネタの解説。これは結構大変。お疲れさまです。
そして、今回の輪講は第12章
「Language models for information retrieval」。
この章は、前章に続いて確率・統計の話。
言語を確率分布で表現する「言語モデル」についてです。
内容の難易度や分量は前章や次章と比べると控えめ。
今回の内容(言語モデル)を適用したハックもどうぞ→[2008-09-07-3]
次回はナイーブベイズ(Naive Bayes)です。
内部ベイズではありません。
前回から1ヶ月あいていたので「夏休みの宿題」(任意)がありました。
IIR に関係する何かをやる、という課題。
輪講終了後に何人かが発表を行いました。
こんなのがありました。
(1) RSS から言語モデルを得て、ランダムな文を生成するハック / 私
(see [2008-09-07-3])
(2) ナイーブベイズによるテキスト分類体験アプリ / sleepy_yoshi
(http://d.hatena.ne.jp/sleepy_yoshi/20080907/p1)
(3) 5章の圧縮を行う Perl Module「Array::Gap」 / id:naoya
(http://d.hatena.ne.jp/naoya/20080906/1220685978)
(4) II簡単実装環境 / id:naoya
(5) Wikipedia データで Variable Byte Code の評価 / yamada
発表は、次回へと続きます。
■Introduction to Information Retrieval

(ref. [2008-08-05-2])
輪講の本。関連書籍というよりも主役書籍。
■荒木雅弘 / フリーソフトでつくる音声認識システム - パターン認識・機械学習の初歩から対話システムまで
(ref. [2007-10-09-4])
今日の言語モデルの話の基礎をカバー。
■徳永健伸 / 情報検索と言語処理

(ref. http://d.hatena.ne.jp/naoya/20080906/1220685978)
東工大の徳永先生による定番本。11章の復習・補足に。
- Introduction to Information Retrieval
http://www-csli.stanford.edu/~hinrich/information-retrieval-book.html
今回は六本木ヒルズの Baidu の会議室を使わせて頂きました。
ありがとうございました。百度!百度!
最初に恒例の「前章の復習 by id:naoya」
(http://d.hatena.ne.jp/naoya/20080907/1220796559)。
前章の確率ネタの解説。これは結構大変。お疲れさまです。
そして、今回の輪講は第12章
「Language models for information retrieval」。
この章は、前章に続いて確率・統計の話。
言語を確率分布で表現する「言語モデル」についてです。
内容の難易度や分量は前章や次章と比べると控えめ。
今回の内容(言語モデル)を適用したハックもどうぞ→[2008-09-07-3]
次回はナイーブベイズ(Naive Bayes)です。
内部ベイズではありません。
夏休みの宿題
前回から1ヶ月あいていたので「夏休みの宿題」(任意)がありました。
IIR に関係する何かをやる、という課題。
輪講終了後に何人かが発表を行いました。
こんなのがありました。
(1) RSS から言語モデルを得て、ランダムな文を生成するハック / 私
(see [2008-09-07-3])
(2) ナイーブベイズによるテキスト分類体験アプリ / sleepy_yoshi
(http://d.hatena.ne.jp/sleepy_yoshi/20080907/p1)
(3) 5章の圧縮を行う Perl Module「Array::Gap」 / id:naoya
(http://d.hatena.ne.jp/naoya/20080906/1220685978)
(4) II簡単実装環境 / id:naoya
(5) Wikipedia データで Variable Byte Code の評価 / yamada
発表は、次回へと続きます。
今日の関連書籍
■Introduction to Information Retrieval
(ref. [2008-08-05-2])
輪講の本。関連書籍というよりも主役書籍。
■荒木雅弘 / フリーソフトでつくる音声認識システム - パターン認識・機械学習の初歩から対話システムまで
(ref. [2007-10-09-4])
今日の言語モデルの話の基礎をカバー。
■徳永健伸 / 情報検索と言語処理
(ref. http://d.hatena.ne.jp/naoya/20080906/1220685978)
東工大の徳永先生による定番本。11章の復習・補足に。
この記事に言及しているこのブログ内の記事
今日のIIR輪講[2008-09-07-2]の内容のフォローも兼ねて、ちょっとしたハックを紹介。
bigram language model に基づく、ランダム文生成を行います。
って、まあ、単純にある単語の次に現れる単語の分布を用いて、文章を生成していくだけですが。
以下、サンプルプログラムと実行例です。
rss-lm.pl
日本語形態素解析に Yahoo!API を使っています。
- テキスト解析:日本語形態素解析API - Yahoo!デベロッパーネットワーク
http://developer.yahoo.co.jp/webapi/jlp/ma/v1/parse.html
$appid は自分で取得したものを使ってくださいね。
(http://e.developer.yahoo.co.jp/webservices/register_application)
追記140605: APIのURLが古いままだったので変更。
- 旧:api.jlp.yahoo.co.jp
- 新:jlp.yahooapis.jp
またプログラムも時代に合わせて(?)一部変更。
RSS の URL を引数に与えて実行します。
実行結果はカオスです!
http://chalow.net/
あと、確かにオフィシャルなスイカ(たぶん国産西瓜のことかと)はおいしいです。
http://d.hatena.ne.jp/naoya/
あまり使ってないんだけどな、最近は。
あと、「何か適当に関する手法」を募集しているようです。
しかも第2回。一発ネタでは終わらないのですね。
RSS(日本語)を読み込んで、テキストを形態素解析し、単語2連続(bigram)をカウントしています(ハッシュ %next_words に格納)。
単語 x の後に y が現れる確率は P(y|x) です。
生成時は、確率 P(y|x) に準じてランダムに y を選びます。
その方法は、
(1) x の次に現れる単語( ...)を重複をゆるすリストに格納する。
...)を重複をゆるすリストに格納する。
という単純なものです。
説明するまでもないと思いますが、こうすることで「は」「も」「の」「から」は、それぞれ P(は|今日)、P(も|今日)、P(の|今日)、P(から|今日)、に準じた確率でランダムに選ばれます。
単語が多い対象では実行性能が悪くなりますが、RSS のテキストくらいの量なら問題ないでしょう。
ランダムで選ばれた単語を出力し、その単語の次に現れる単語をまたランダムで選ぶ、ということをループさせることにより文章を生成していきます。
なお、空文字の単語は「文頭または文末」を意味しています。
ループの最初は空文字からスタートさせます。
JavaScript 版と PHP 版。生成のロジックは同じです。
- マルコフ連鎖で文章生成(JavaScript) - エブログ
http://ablog.seesaa.net/article/20987336.html
- Yahoo!のAPIを利用してマルコフ連鎖で文章生成(php)
http://shohoji.net/blog/archives/001723.html
trigram (3gram) によるモデル。
- mizzy.org : perlで人工無脳 #1
http://blog.mizzy.org/articles/2005/06/19/bot01
確率文章生成を含む、いろんな人工無脳について。
- 人工無脳レビュー
http://www.ycf.nanet.co.jp/~skato/muno/material/review.html
いくつかの RSS でやってみたサンプル集。
- いろんなブログのRSSで文章生成してみた (ヲハニュース)
http://d.hatena.ne.jp/yto/20080906/p5
bigram language model に基づく、ランダム文生成を行います。
って、まあ、単純にある単語の次に現れる単語の分布を用いて、文章を生成していくだけですが。
以下、サンプルプログラムと実行例です。
サンプルコード
rss-lm.pl
#!/usr/bin/perl
use strict;
use warnings;
use XML::RSS;
use LWP::Simple;
use XML::Simple;
use URI::Escape;
use utf8;
binmode STDOUT, ":utf8";
my $appid = "YahooDemo";
my $rss_url = shift;
my $rss_cont = get($rss_url) || "";
my $rss = XML::RSS->new;
$rss->parse($rss_cont);
my %next_words;
my $pre = "";
foreach my $i (@{$rss->{items}}) {
my $ma_ref = webma($i->{title}."\n".$i->{description});
foreach my $mo (@{$ma_ref->{ma_result}->{word_list}->{word}}) {
my $w = $mo->{surface};
$w = "" if ref($w) eq "HASH";
next if ($pre eq "" and $w eq "");
push @{$next_words{$pre}}, $w;
$pre = $w;
}
}
my @words;
my $cur = "";
for (my $i = 0; $i < 200; $i++) {
my $tmp = $next_words{$cur};
$cur = $tmp->[rand(@$tmp)];
last if $cur eq "" and $i > 100;
push @words, $cur;
}
print join("", @words), "\n";
sub webma {
my ($key) = @_;
my $url = "http://jlp.yahooapis.jp/MAService/V1/parse"
."?appid=$appid&results=ma&response=surface"
."&sentence=".URI::Escape::uri_escape_utf8($key);
return {} if length($url) > 10000;
my $response = get($url);
my $xmlsimple = XML::Simple->new(ForceArray => [ 'word' ]);
return $xmlsimple->XMLin($response);
}
日本語形態素解析に Yahoo!API を使っています。
- テキスト解析:日本語形態素解析API - Yahoo!デベロッパーネットワーク
http://developer.yahoo.co.jp/webapi/jlp/ma/v1/parse.html
$appid は自分で取得したものを使ってくださいね。
(http://e.developer.yahoo.co.jp/webservices/register_application)
追記140605: APIのURLが古いままだったので変更。
- 旧:api.jlp.yahoo.co.jp
- 新:jlp.yahooapis.jp
またプログラムも時代に合わせて(?)一部変更。
実行例
RSS の URL を引数に与えて実行します。
実行結果はカオスです!
http://chalow.net/
./rss-lm.pl http://chalow.net/cl.rdf
【初めての持ちが、ハーゲンダッツの会)ブログで焼いて、その他のひみつ][2008北海道へ行かなくて。場所は、彼のエコアート。ローマ人のスーパーでは一個29,400円は、-04-03-08-基本的な味で売っていた!描画がFX35-KChromeLUMIXでも、デニムの大和路[2008特にhttp://wassr...blog.com/2008受賞作品展」というかとか西麻布でオフィシャルにスイカを置いておいしいです。「北海道へ行かなくて。場所は、彼のエコアート。」ってのは、ポエムな感じで素敵です。
あと、確かにオフィシャルなスイカ(たぶん国産西瓜のことかと)はおいしいです。
http://d.hatena.ne.jp/naoya/
./rss-lm.pl http://d.hatena.ne.jp/naoya/rss
SKK分だけ、はてなハイクの発表を受けはてなハイクのインターンもbyteArray::Gapでした。金曜日はアルゴリズムの頃、はてなハイクのたつをさんから、あの変換スタイルにやろうと言えばThriftcodesKansai.net/~naoya1977/about-thrift/naoya/naoya1977/インフラを終えて発表資料を試みました。という課題が終わり、計算機科学にアップロードしましたことから何か適当に関する手法第2回募集ついに「はてなハイクのたつをさん」になってしまいました!
あまり使ってないんだけどな、最近は。
あと、「何か適当に関する手法」を募集しているようです。
しかも第2回。一発ネタでは終わらないのですね。
簡単な解説
RSS(日本語)を読み込んで、テキストを形態素解析し、単語2連続(bigram)をカウントしています(ハッシュ %next_words に格納)。
単語 x の後に y が現れる確率は P(y|x) です。
生成時は、確率 P(y|x) に準じてランダムに y を選びます。
その方法は、
(1) x の次に現れる単語(
例:「今日」→「は」「も」「の」「の」「は」「から」「は」「の」(2) そのリストから一つランダムで選ぶ。
(x = 「今日」)
という単純なものです。
説明するまでもないと思いますが、こうすることで「は」「も」「の」「から」は、それぞれ P(は|今日)、P(も|今日)、P(の|今日)、P(から|今日)、に準じた確率でランダムに選ばれます。
単語が多い対象では実行性能が悪くなりますが、RSS のテキストくらいの量なら問題ないでしょう。
ランダムで選ばれた単語を出力し、その単語の次に現れる単語をまたランダムで選ぶ、ということをループさせることにより文章を生成していきます。
なお、空文字の単語は「文頭または文末」を意味しています。
ループの最初は空文字からスタートさせます。
関連リンク
JavaScript 版と PHP 版。生成のロジックは同じです。
- マルコフ連鎖で文章生成(JavaScript) - エブログ
http://ablog.seesaa.net/article/20987336.html
- Yahoo!のAPIを利用してマルコフ連鎖で文章生成(php)
http://shohoji.net/blog/archives/001723.html
trigram (3gram) によるモデル。
- mizzy.org : perlで人工無脳 #1
http://blog.mizzy.org/articles/2005/06/19/bot01
確率文章生成を含む、いろんな人工無脳について。
- 人工無脳レビュー
http://www.ycf.nanet.co.jp/~skato/muno/material/review.html
いくつかの RSS でやってみたサンプル集。
- いろんなブログのRSSで文章生成してみた (ヲハニュース)
http://d.hatena.ne.jp/yto/20080906/p5
この記事に言及しているこのブログ内の記事
- マルコフ連鎖と形態素解析でランダムな文章を生成する (2023-06-08)
- 【ヲハニュース 2022年1月18日号】国会図書館サイトで絶版本ネット閲覧可能に、バレンタインデーが世界一流ショコラティエが集まるチョコのコミケに、など (2022-01-18)
- 青空文庫のテキストデータの一括ダウンロード方法 (2018-07-25)
- 指定した確率分布に従った乱数発生を効率的に行う「別名法 (alias method)」を Perl で実装してみた (2014-04-16)
- Google 翻訳の英日翻訳の品質について (2008-09-17)
- 「Introduction to Information Retrieval」輪講第13回 (2008-09-07)
恵比寿ガーデンプレイスにいたハトを撮ってみただけ。

この写真、上部の親子連れの足がもうちょっとフレームに入っていたら楽しげな写真になったのになあ。でも、動く鳩を撮りまくってるときにはそんなとこに気が回らないよな。
■Panasonic デジタルカメラ LUMIX FX35 DMC-FX35-K

この写真、上部の親子連れの足がもうちょっとフレームに入っていたら楽しげな写真になったのになあ。でも、動く鳩を撮りまくってるときにはそんなとこに気が回らないよな。
■Panasonic デジタルカメラ LUMIX FX35 DMC-FX35-K
恵比寿で雨にふられるも家族連れIT系に遭遇
2008-09-07-5
[Diary]
最近よくあることだけど、IIR輪講会から恵比寿に戻って来たら、夕立ですごい雨。
地下鉄の出口で id:overlast と途方にくれる。
で、どこかでお茶でもするかと思うも、駅周辺はどこも満員。
じゃあ恵比寿ガーデンプレイスへ行くか(濡れずに行ける)、ということで、アトレ(駅ビル)の中を通っていると、サイ○ウズラ○の Z 一家(3人)と遭遇。
もうちょっと進むと、「は○な」の K 一家(3人)とも遭遇。
一体全体なんなんでしょう。
結局、Z 一家とガーデンプレイスで、「わっふるわっふる」でした。

奥さんは優香に似てカワイイ系です。
地下鉄の出口で id:overlast と途方にくれる。
で、どこかでお茶でもするかと思うも、駅周辺はどこも満員。
じゃあ恵比寿ガーデンプレイスへ行くか(濡れずに行ける)、ということで、アトレ(駅ビル)の中を通っていると、サイ○ウズラ○の Z 一家(3人)と遭遇。
もうちょっと進むと、「は○な」の K 一家(3人)とも遭遇。
一体全体なんなんでしょう。
結局、Z 一家とガーデンプレイスで、「わっふるわっふる」でした。
奥さんは優香に似てカワイイ系です。
この記事に言及しているこのブログ内の記事
たつをの ChangeLog
Powered by chalow