ウェブサービス(Web API)をプログラムから使う
2009-12-26-2
[WebAPI][Programming]
前回[2009-12-24-1]はウェブサービス(Web API)の基本的事項と、よく採用されているプロトコルとデータ構造の概要を解説した。
プロトコルとデータ構造の組み合わせ、計4つのうち3つを取り上げて、実際にプログラムから Web API を使う方法を例を用いて説明する。
今回取り上げるサンプルプログラムで使った Web API と用いたプログラム言語を表に示す:
Web API をREST風プロトコルでアクセスしXMLデータを得る流れを perl のサンプルプログラムで示す。
下記に示すサンプルプログラム(fsj.pl)では、日本語文を形態素解析(≒単語に分割する)する MECAPI API (MeCab Web Service, https://maapi.net/) を用いた。
入力として与えられた日本語文を単語分割し、固有名詞(人名、組織名、地名など)の部分だけ伏せ字にする。
fsj.pl :
使い方:コマンドラインから実行。
Perl で Web API を使う際の基本となるモジュールは下記の通り。
- LWP::Simple : URLを与えるとウェブページを文字列として取得してくれる。
- XML::Simple : XMLのパーザ。
- URI::Escape : 文字列を URL encode してくれる(例:"走"→"%E8%B5%B0")。
関数 mecapi でウェブアクセスからXMLのパーズまで行っている。XML::Simple の ForceArray により、解析結果中の word が配列として格納される(→@$r_ref)。
MECAPI では各 word には surface(表層文字列)と feature(品詞や読みなどの情報)を持つ。@$r_ref のループ(foreach)内では、feature を見て「固有名詞」であれば表層文字列の文字数分伏せ字「X」を、そうではければ表層文字列をそのまま表示する。
MECAPI の解析結果XMLを再掲(ref. [2009-12-24-1]):
Web API をXMLRPCでアクセスしXMLデータを得る流れを perl のサンプルプログラムで示す。
サンプルプログラム(hbn.pl)では「はてなブックマーク件数取得API」を用いる。
- はてなブックマーク件数取得APIとは
http://d.hatena.ne.jp/keyword/%a4%cf%a4%c6%a4%ca%a5%d6%a5%c3%a5%af%a5%de%a1%bc%a5%af%b7%ef%bf%f4%bc%e8%c6%c0API?kid=146686
「はてなブックマーク」(http://b.hatena.ne.jp/) とはソーシャルブックマークの一つで、ネット上で共有できるブックマークサービスである。あるページに対してのユーザがブックマークした合計数を知ることができるので、そのページの「人気」が分かる。
「はてなブックマーク件数取得API」は、URLに対してブックマークの合計数(被ブクマ数)を得るためのAPIである。GETメソッドでは一つのURLに対する被ブクマ数を得ることができる。POSTメソッド(XML-RPC)では複数のURLの被ブクマ数を一気に得ることができる。
下記に示すサンプルプログラム(hbn.pl)では、後者の XML-RPC を用い、入力として与えられた複数のURLの被ブクマ数を一気に得る。
hbn.pl :
使い方:コマンドラインから実行。
Perl で XML-RPC を使う際は XMLRPC::Lite が便利。
なお、はてなブックマーク件数取得API (XMLRPC) は下記の実験サイトで使用している。
たつを検索はてブ順
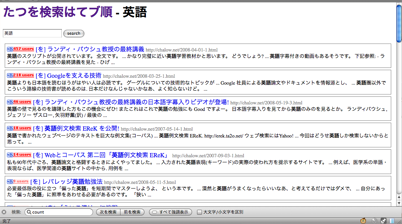
URL:http://search.chalow.net/
公開日:7/14 [2008-07-14-2]
概要:Yahoo! Search BOSS [2008-07-11-3]で、このブログの記事を検索し、はてなブックマーク数の多い順に表示する。
Web API を JavaScript からアクセスしJSONPデータを得てクライアント側で処理する流れをサンプルプログラムで示す。
Yahoo!デベロッパーネットワーク(YDN)のキーフレーズ抽出APIを用いる。
- Yahoo!デベロッパーネットワーク - テキスト解析 - キーフレーズ抽出
http://developer.yahoo.co.jp/webapi/jlp/keyphrase/v1/extract.html
キーフレーズ抽出APIは、テキストを渡すとそこに含まれる重要そうなフレーズを重要度付きで抽出してくれるAPIである。
解析結果のデータ構造は XML, JSON, JSONP に対応している。
入力されたテキストをキーフレーズ抽出APIに渡し、結果をJSONPで受け取り、タグクラウドとして表示するプログラム(ウェブページ)のURLと簡易化したコードを下記に示す。
- キーフレーズ抽出タグクラウド風
http://yapi.ta2o.net/demos/kp.html (see also →[2009-07-09-3])
キーフレーズ抽出タグクラウド風(簡易版):
script タグの内側の JavaScript コードは、JSONP を使う際の定番パターンである。
ボタンが押されると、入力されたテキストが getElementById で取得され、Web API アクセス用の URL が生成され(script.id)、そのアクセス結果である JSONP データが動き出す。
このコードでは、解析結果の JSONP は下記のようになっている:
なお、YDN の appid は自分で取得したものをご利用されたい。
下記から取得できる。
http://e.developer.yahoo.co.jp/webservices/register_application
- Wikipedia:Webサービス
- [を] ウェブサービス(Web API)とは?[2009-12-24-1]
プロトコルとデータ構造の組み合わせ、計4つのうち3つを取り上げて、実際にプログラムから Web API を使う方法を例を用いて説明する。
今回取り上げるサンプルプログラムで使った Web API と用いたプログラム言語を表に示す:
| プロトコル\データ構造 | XML | JSON, JSONP |
| REST風 | MECAPI, Perl | キーフレーズ抽出API, JavaScript |
| SOAP, XML-RPC | はてブ件数取得API, Perl | - |
REST風 + XML
Web API をREST風プロトコルでアクセスしXMLデータを得る流れを perl のサンプルプログラムで示す。
下記に示すサンプルプログラム(fsj.pl)では、日本語文を形態素解析(≒単語に分割する)する MECAPI API (MeCab Web Service, https://maapi.net/) を用いた。
入力として与えられた日本語文を単語分割し、固有名詞(人名、組織名、地名など)の部分だけ伏せ字にする。
fsj.pl :
#!/usr/bin/perl
use strict;
use warnings;
use LWP::Simple;
use XML::Simple;
use URI::Escape;
use Encode;
use utf8;
use open ':utf8';
binmode STDIN, ":utf8";
binmode STDOUT, ":utf8";
while (<>) {
chomp;
next unless $_;
my $r_ref = mecapi({sentence => $_});
my $new_sentence = "";
foreach my $w (@$r_ref) {
if ($w->{feature} =~ /,固有名詞,/) {
$new_sentence .= "X" x length($w->{surface});
} else {
$new_sentence .= $w->{surface};
}
}
print "$new_sentence\n";
}
sub mecapi {
my ($args_ref) = @_;
my $s = URI::Escape::uri_escape_utf8($args_ref->{sentence}) || "";
my $url = "https://maapi.net/apis/mecapi?sentence=$s";
my $response = get($url);
my $xmlsimple = XML::Simple->new(ForceArray => [ 'word' ]);
my $xml = $xmlsimple->XMLin($response);
return $xml->{word};
}
使い方:コマンドラインから実行。
% cat a.txt 今日は鈴木君と渋谷のマクドナルドでコーヒーやコカコーラを飲みました。 % ./fsj.pl a.txt 今日はXX君とXXのXXXXXXでコーヒーやXXXXXを飲みました。
Perl で Web API を使う際の基本となるモジュールは下記の通り。
- LWP::Simple : URLを与えるとウェブページを文字列として取得してくれる。
- XML::Simple : XMLのパーザ。
- URI::Escape : 文字列を URL encode してくれる(例:"走"→"%E8%B5%B0")。
関数 mecapi でウェブアクセスからXMLのパーズまで行っている。XML::Simple の ForceArray により、解析結果中の word が配列として格納される(→@$r_ref)。
MECAPI では各 word には surface(表層文字列)と feature(品詞や読みなどの情報)を持つ。@$r_ref のループ(foreach)内では、feature を見て「固有名詞」であれば表層文字列の文字数分伏せ字「X」を、そうではければ表層文字列をそのまま表示する。
MECAPI の解析結果XMLを再掲(ref. [2009-12-24-1]):
(https://maapi.net/apis/mecapi?sentence=%E3%83%9A%E3%83%B3%E3%81%AF%E8%B5%B0%E3%82%8B)<MecabResult> <word> <surface>ペン</surface> <feature>名詞,一般,*,*,*,*,ペン,ペン,ペン</feature> </word> <word> <surface>は</surface> <feature>助詞,係助詞,*,*,*,*,は,ハ,ワ</feature> </word> <word> <surface>走る</surface> <feature>動詞,自立,*,*,五段・ラ行,基本形,走る,ハシル,ハシル</feature> </word> </MecabResult>
XML-RPC + XML
Web API をXMLRPCでアクセスしXMLデータを得る流れを perl のサンプルプログラムで示す。
サンプルプログラム(hbn.pl)では「はてなブックマーク件数取得API」を用いる。
- はてなブックマーク件数取得APIとは
http://d.hatena.ne.jp/keyword/%a4%cf%a4%c6%a4%ca%a5%d6%a5%c3%a5%af%a5%de%a1%bc%a5%af%b7%ef%bf%f4%bc%e8%c6%c0API?kid=146686
「はてなブックマーク」(http://b.hatena.ne.jp/) とはソーシャルブックマークの一つで、ネット上で共有できるブックマークサービスである。あるページに対してのユーザがブックマークした合計数を知ることができるので、そのページの「人気」が分かる。
「はてなブックマーク件数取得API」は、URLに対してブックマークの合計数(被ブクマ数)を得るためのAPIである。GETメソッドでは一つのURLに対する被ブクマ数を得ることができる。POSTメソッド(XML-RPC)では複数のURLの被ブクマ数を一気に得ることができる。
下記に示すサンプルプログラム(hbn.pl)では、後者の XML-RPC を用い、入力として与えられた複数のURLの被ブクマ数を一気に得る。
hbn.pl :
#!/usr/bin/perl
use strict;
use warnings;
use XMLRPC::Lite;
my @urls;
while (<>) {
chomp;
next unless /^http/;
push @urls, $_;
}
my $EndPoint = 'http://b.hatena.ne.jp/xmlrpc';
my $map = XMLRPC::Lite
->proxy($EndPoint)
->call('bookmark.getCount', @urls)
->result;
foreach my $url (@urls) {
my $num = $map->{$url} || 0;
my $hbu = $url;
$hbu =~ s{^https?://}{http://b.hatena.ne.jp/entry/};
print "$num $hbu\n";
}
使い方:コマンドラインから実行。
% cat hbn-test.txt
http://www.yahoo.co.jp/
http://chalow.net/2009-06-16-1.html
http://chalow.net/2009-08-15-1.html
http://chalow.net/
% ./hbn.pl hbn-test.txt
6827 http://b.hatena.ne.jp/entry/www.yahoo.co.jp/
939 http://b.hatena.ne.jp/entry/chalow.net/2009-06-16-1.html
506 http://b.hatena.ne.jp/entry/chalow.net/2009-08-15-1.html
134 http://b.hatena.ne.jp/entry/chalow.net/
Perl で XML-RPC を使う際は XMLRPC::Lite が便利。
なお、はてなブックマーク件数取得API (XMLRPC) は下記の実験サイトで使用している。
たつを検索はてブ順
URL:http://search.chalow.net/
公開日:7/14 [2008-07-14-2]
概要:Yahoo! Search BOSS [2008-07-11-3]で、このブログの記事を検索し、はてなブックマーク数の多い順に表示する。
REST風 + JSONP
Web API を JavaScript からアクセスしJSONPデータを得てクライアント側で処理する流れをサンプルプログラムで示す。
Yahoo!デベロッパーネットワーク(YDN)のキーフレーズ抽出APIを用いる。
- Yahoo!デベロッパーネットワーク - テキスト解析 - キーフレーズ抽出
http://developer.yahoo.co.jp/webapi/jlp/keyphrase/v1/extract.html
キーフレーズ抽出APIは、テキストを渡すとそこに含まれる重要そうなフレーズを重要度付きで抽出してくれるAPIである。
解析結果のデータ構造は XML, JSON, JSONP に対応している。
入力されたテキストをキーフレーズ抽出APIに渡し、結果をJSONPで受け取り、タグクラウドとして表示するプログラム(ウェブページ)のURLと簡易化したコードを下記に示す。
- キーフレーズ抽出タグクラウド風
http://yapi.ta2o.net/demos/kp.html (see also →[2009-07-09-3])
キーフレーズ抽出タグクラウド風(簡易版):
<html>
<head>
<meta http-equiv="Content-Type" content="text/html;charset=UTF-8">
<title>キーフレーズ抽出タグクラウド風(Simple)</title>
<script>
function disp(json){
var q = '';
for (var k in json) {
q += '<span style="font-size:'+json[k]+'px;margin:10px;">'+k+'</span> ';
}
document.getElementById('dsp').innerHTML = q;
};
function dJSON(cb){
this.proxy = 'http://jlp.yahooapis.jp/KeyphraseService/V1/extract';
this.cb = cb;
this.parse = function(cb){
var q = document.getElementById('txt').value;
var script = document.createElement('script');
script.id = this.proxy + '?appid=THISISAPEN' +
'&output=json' + '&callback=' + this.cb + '&sentence=' + encodeURI(q);
script.charset = 'UTF-8';
script.src = script.id;
document.lastChild.appendChild(script);
};
return this;
}
var djson = new dJSON('disp');
</script>
</head>
<body>
<input type="button" onclick="javascript:djson.parse();" value="do">
<input type="text" size="60"id="txt">
<div id="dsp"></div>
</body>
</html>
script タグの内側の JavaScript コードは、JSONP を使う際の定番パターンである。
ボタンが押されると、入力されたテキストが getElementById で取得され、Web API アクセス用の URL が生成され(script.id)、そのアクセス結果である JSONP データが動き出す。
このコードでは、解析結果の JSONP は下記のようになっている:
disp({"\u30a8\u30d3\u30b9":100,"\u30da\u30f3":59})
タグクラウドをブラウザ上に表示する関数 disp が、抽出フレーズとの重要度(Max 100)を引数に呼ばれることになる。なお、YDN の appid は自分で取得したものをご利用されたい。
下記から取得できる。
http://e.developer.yahoo.co.jp/webservices/register_application
参考
- Wikipedia:Webサービス
- [を] ウェブサービス(Web API)とは?[2009-12-24-1]
この記事に言及しているこのブログ内の記事