たつをの ChangeLog : 2016-10-17
昔から使っている、「なんちゃってテキストマイニング」用の簡単なPerlスクリプトがあるのですが、最近少し手直ししたので公開しておきます。
やってることは、日本語テキストから都道府県名を取ってくるってだけ。
マッチした都道府県名を行末に追加していきます。
詳しくは実行例をごらんください。
■コード: kengrep.pl
■実行例:(スペース連続=タブ文字)
やってることは、日本語テキストから都道府県名を取ってくるってだけ。
マッチした都道府県名を行末に追加していきます。
詳しくは実行例をごらんください。
■コード: kengrep.pl
#!/usr/bin/env perl
use strict;
use warnings;
use Getopt::Long;
use utf8;
use open ":utf8";
binmode STDIN, ":utf8";
binmode STDOUT, ":utf8";
my @tdhks = qw(
愛知県 青森県 秋田県 石川県 茨城県 岩手県 愛媛県 大分県
大阪府 岡山県 沖縄県 香川県 鹿児島県 神奈川県 岐阜県 京都府
熊本県 群馬県 高知県 埼玉県 佐賀県 滋賀県 静岡県 島根県
千葉県 東京都 徳島県 栃木県 鳥取県 富山県 長崎県 長野県
奈良県 新潟県 兵庫県 広島県 福井県 福岡県 福島県 北海道
三重県 宮城県 宮崎県 山形県 山口県 山梨県 和歌山県
);
my $key_at_str = 0; # key=POS : process only POS-th column. origin 1
my $prefix_mode = 0; # 1: [都府県]より前の文字列だけでマッチ
my $show_all_kens = 0; # 1:マッチした都道府県を全部出す(CSV)
my $matched_lines_only = 0; # 1:マッチした行のみ出力
GetOptions (
'k|key=s' => \$key_at_str,
'p|prefix' => \$prefix_mode,
'a|all' => \$show_all_kens,
'm|match' => \$matched_lines_only,
);
if ($prefix_mode) {
s/[都府県]$// for @tdhks;
}
my $tdhk_pat = join("|", @tdhks);
while (<>) {
chomp;
my $line = $_;
$_ = (split(/\t/, $_))[$key_at_str-1] if $key_at_str;
my %seen;
my $k = join(",", grep {not $seen{$_}++} /($tdhk_pat)/g);
$k =~ s/,.+$// if not $show_all_kens;
next if $matched_lines_only and $k eq "";
print join("\t", $line, $k)."\n";
}
■実行例:(スペース連続=タブ文字)
% cat kengrep-test.txt 1 場所は東京都渋谷区 2 たぶん神奈川県、埼玉県、千葉県あたりが通勤可能圏内です 3 みかんといえば愛媛や和歌山や静岡など 4 東京ディスニーランドは千葉県にあります 5 北海道から沖縄まで 6 山口さんちのツムトくん ### 第2カラムのみを処理対象 (-k 2) % ./kengrep.pl -k 2 kengrep-test.txt 1 場所は東京都渋谷区 東京都 2 たぶん神奈川県、埼玉県、千葉県あたりが通勤可能圏内です 神奈川県 3 みかんといえば愛媛や和歌山や静岡など 4 東京ディスニーランドは千葉県にあります 千葉県 5 北海道から沖縄まで 北海道 6 山口さんちのツムトくん ### マッチした行だけ表示 (-m) % ./kengrep.pl -k 2 kengrep-test.txt -m 1 場所は東京都渋谷区 東京都 2 たぶん神奈川県、埼玉県、千葉県あたりが通勤可能圏内です 神奈川県 4 東京ディスニーランドは千葉県にあります 千葉県 5 北海道から沖縄まで 北海道 ### "都府県" 抜きでもマッチ (-p) % ./kengrep.pl -k 2 kengrep-test.txt -m -p 1 場所は東京都渋谷区 東京 2 たぶん神奈川県、埼玉県、千葉県あたりが通勤可能圏内です 神奈川 3 みかんといえば愛媛や和歌山や静岡など 愛媛 4 東京ディスニーランドは千葉県にあります 東京 5 北海道から沖縄まで 北海道 6 山口さんちのツムトくん 山口 ### マッチした都道府県すべてを表示 (-a) % ./kengrep.pl -k 2 kengrep-test.txt -m -p -a 1 場所は東京都渋谷区 東京 2 たぶん神奈川県、埼玉県、千葉県あたりが通勤可能圏内です 神奈川,埼玉,千葉 3 みかんといえば愛媛や和歌山や静岡など 愛媛,和歌山,静岡 4 東京ディスニーランドは千葉県にあります 東京,千葉 5 北海道から沖縄まで 北海道,沖縄 6 山口さんちのツムトくん 山口 % ./kengrep.pl -k 2 kengrep-test.txt -m -a 1 場所は東京都渋谷区 東京都 2 たぶん神奈川県、埼玉県、千葉県あたりが通勤可能圏内です 神奈川県,埼玉県,千葉県 4 東京ディスニーランドは千葉県にあります 千葉県 5 北海道から沖縄まで 北海道
関連記事
アマゾンアソシエイトのかなり古いレポートをダウンロードする方法
2016-10-17-2
[Affiliate]
Amazon のアソシエイトレポートの古いレポートをダウンロードする方法について解説します。売上げレポートのTSV形式でのダウンロードを念頭に説明。
基本的な話として、「期間を指定する」で指定してから「TSV形式でダウンロード」ボタンをクリックすると "report.txt" というファイルがゲットできます。
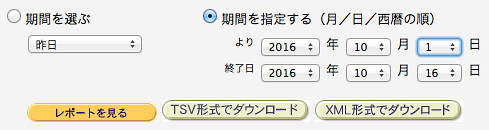
しかし、指定できる「年」が5年前までという問題が。もっと古いのが欲しい場合はどうしたらよいのでしょうか?
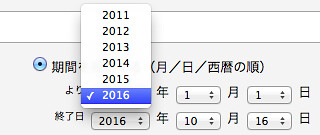
ここで、「TSV形式でダウンロード」ボタンを押した直後のURLを見てみましょう。こんな感じです。
重要なのは下記の6つのパラメータ。
これらのパラメータでレポートの開始年月日と終了年月日を指定すれば良いのです。これで開始年(startYear)が5年よりも前のレポートもダウンロードできます。具体的には、さきほど挙げたURLの該当部分を書き換えたのちブラウザのアドレス欄へコピーしてアクセス! それだけ!
月(startMonth,endMonth)の指定には注意。10月の場合は9、1月の場合は0、6月は5、と一つ小さい値を指定します。
例えば、2007年7月1日から2007年12月31日の期間の指定方法:
なお、古いレポートがダウンロードできるとはいえ10年前までが限度みたいです。私はそれよりも数年前にアマゾンアソシエイトを始めているんですが、当初のデータは結局ゲットできず。でも10年分あればいいや。
基本的な話として、「期間を指定する」で指定してから「TSV形式でダウンロード」ボタンをクリックすると "report.txt" というファイルがゲットできます。
しかし、指定できる「年」が5年前までという問題が。もっと古いのが欲しい場合はどうしたらよいのでしょうか?
ここで、「TSV形式でダウンロード」ボタンを押した直後のURLを見てみましょう。こんな感じです。
重要なのは下記の6つのパラメータ。
... &startYear=2016 &startMonth=0 &startDay=1 &endYear=2016 &endMonth=9 &endDay=16 &...
これらのパラメータでレポートの開始年月日と終了年月日を指定すれば良いのです。これで開始年(startYear)が5年よりも前のレポートもダウンロードできます。具体的には、さきほど挙げたURLの該当部分を書き換えたのちブラウザのアドレス欄へコピーしてアクセス! それだけ!
月(startMonth,endMonth)の指定には注意。10月の場合は9、1月の場合は0、6月は5、と一つ小さい値を指定します。
例えば、2007年7月1日から2007年12月31日の期間の指定方法:
...&startYear=2007&startMonth=6&startDay=1 &endYear=2007&endMonth=11&endDay=31&...
なお、古いレポートがダウンロードできるとはいえ10年前までが限度みたいです。私はそれよりも数年前にアマゾンアソシエイトを始めているんですが、当初のデータは結局ゲットできず。でも10年分あればいいや。
たつをの ChangeLog
Powered by chalow