検索におけるテキスト走査とインデックス
2008-01-19-5
[IIR]
「Introduction to Information Retrieval」[1]の第一章[2008-01-12-1]
の1.1にの冒頭に出てきた、
「テキスト走査による方法とインデックスによる方法の違い」
をまとめました。
この手の導入的解説は、
私も過去の論文等の冒頭で何度も書いていたりするのですが、
今回、IIRをベースに改めて整理してみました。
§
文書集合から検索質問に合致する文書を検索するために実装は、
「テキスト走査」による方法と
「インデックス」による方法の大きく二つに分けられる(図)。
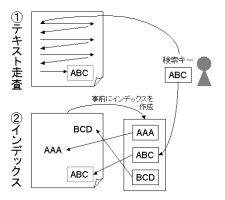
テキスト走査(文字列照合 (string pattern maching)[2])による方法は、
単純に文書集合の先頭から最後まで検索キーを順番に照合していく。
最低でも1回は最後まで走査しなければならないので、
文書集合のサイズを N とすれば計算量は O(N) となる。
有名な実装として、UNIX系の grep が知られている。
指定したファイル名(複数ファイルも可能)に対して、
与えられたキーワードを順次照合し、合致した文書(デフォルトでは行)
を出力するというソフトウェアである。
近年のマシン環境においてはこのような単純な方法でも
高速に利用できる機会が多い。
例えば、自分が書いた全ての論文、原稿を検索するなど、
検索対象が把握できる分量であれば実用上問題はない。
走査を高速化するためのさまざまな工夫が試みられている。
例えば、検索キー文字列を事前に処理し照合回数を減らす
KMP法 (Knuth-Morris-Pratt法) や
BM法 (Boyer-Moore法) が多く用いられている。
これに対し、インデックスによる方法は、
事前に索引 (index) を作ることで検索を高速化する。
一冊の書籍を検索対象として検索する場合、
索引がなければ最初のページからテキスト走査を行う必要があるが、
索引があればそれを引くだけで目的のページが分かる。
インデックスによる方法の最大の利点は、
大規模な文書集合に対して高速に検索できる点である。
例えば、
ウェブ検索のようにペタバイトレベルのデータを対象とする場合、
O(N) のテキスト走査による方法は実用上ほぼ不可能である。
インデックスのもう一つの大きな利点は、
検索結果のランキングが容易であるという点である。
これは文書集合を事前処理することにより得られる情報
(単語出現頻度など)を用いることで実現できる。
もちろんテキスト走査でも、
ランキング表を内部に保持しつつ走査することで実現できるが、
ランキング表が大きい場合や検索キーワードが多い場合に不利である。
テキスト走査による方法の最大の利点は、
利用も実装も手軽であることである。
インデックスを用意する必要がないため、
いつでもすぐに検索が実行できる。
また、頭からスキャンするという単純な処理のため
初歩的なプログラミングの知識だけで実装が可能である。
テキスト走査のもう一つの利点として、
正規表現 (regular expression) などを利用して
検索質問の自由度を高めることができる点がある。
例えば、西暦100年から999年までの表現を含む文書を探す場合、
テキスト走査による方法では
正規表現「西暦[1-9][0-9][0-9]年」で検索すれば良いが、
インデックスによる方法ではあらかじめこのような検索質問を想定して
インデックスを用意しなければならない。
参考文献:
[1] Christopher D. Manning, Prabhakar Raghavan and Hinrich Schu"tze:
Introduction to Information Retrieval, Cambridge University Press, 2008.
(http://www-csli.stanford.edu/~hinrich/information-retrieval-book.html)
[2] 北研二, 津田和彦, 獅々堀正幹: 情報検索アルゴリズム,
共立出版, 2002.
(間違いや補足などありましたら下記フォームからご連絡頂けると幸いです)
の1.1にの冒頭に出てきた、
「テキスト走査による方法とインデックスによる方法の違い」
をまとめました。
この手の導入的解説は、
私も過去の論文等の冒頭で何度も書いていたりするのですが、
今回、IIRをベースに改めて整理してみました。
§
文書集合から検索質問に合致する文書を検索するために実装は、
「テキスト走査」による方法と
「インデックス」による方法の大きく二つに分けられる(図)。
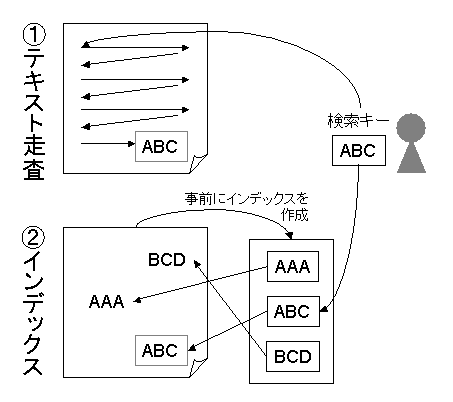
テキスト走査(文字列照合 (string pattern maching)[2])による方法は、
単純に文書集合の先頭から最後まで検索キーを順番に照合していく。
最低でも1回は最後まで走査しなければならないので、
文書集合のサイズを N とすれば計算量は O(N) となる。
有名な実装として、UNIX系の grep が知られている。
指定したファイル名(複数ファイルも可能)に対して、
与えられたキーワードを順次照合し、合致した文書(デフォルトでは行)
を出力するというソフトウェアである。
近年のマシン環境においてはこのような単純な方法でも
高速に利用できる機会が多い。
例えば、自分が書いた全ての論文、原稿を検索するなど、
検索対象が把握できる分量であれば実用上問題はない。
走査を高速化するためのさまざまな工夫が試みられている。
例えば、検索キー文字列を事前に処理し照合回数を減らす
KMP法 (Knuth-Morris-Pratt法) や
BM法 (Boyer-Moore法) が多く用いられている。
これに対し、インデックスによる方法は、
事前に索引 (index) を作ることで検索を高速化する。
一冊の書籍を検索対象として検索する場合、
索引がなければ最初のページからテキスト走査を行う必要があるが、
索引があればそれを引くだけで目的のページが分かる。
インデックスによる方法の最大の利点は、
大規模な文書集合に対して高速に検索できる点である。
例えば、
ウェブ検索のようにペタバイトレベルのデータを対象とする場合、
O(N) のテキスト走査による方法は実用上ほぼ不可能である。
インデックスのもう一つの大きな利点は、
検索結果のランキングが容易であるという点である。
これは文書集合を事前処理することにより得られる情報
(単語出現頻度など)を用いることで実現できる。
もちろんテキスト走査でも、
ランキング表を内部に保持しつつ走査することで実現できるが、
ランキング表が大きい場合や検索キーワードが多い場合に不利である。
テキスト走査による方法の最大の利点は、
利用も実装も手軽であることである。
インデックスを用意する必要がないため、
いつでもすぐに検索が実行できる。
また、頭からスキャンするという単純な処理のため
初歩的なプログラミングの知識だけで実装が可能である。
テキスト走査のもう一つの利点として、
正規表現 (regular expression) などを利用して
検索質問の自由度を高めることができる点がある。
例えば、西暦100年から999年までの表現を含む文書を探す場合、
テキスト走査による方法では
正規表現「西暦[1-9][0-9][0-9]年」で検索すれば良いが、
インデックスによる方法ではあらかじめこのような検索質問を想定して
インデックスを用意しなければならない。
参考文献:
[1] Christopher D. Manning, Prabhakar Raghavan and Hinrich Schu"tze:
Introduction to Information Retrieval, Cambridge University Press, 2008.
(http://www-csli.stanford.edu/~hinrich/information-retrieval-book.html)
[2] 北研二, 津田和彦, 獅々堀正幹: 情報検索アルゴリズム,
共立出版, 2002.
(間違いや補足などありましたら下記フォームからご連絡頂けると幸いです)
この記事に言及しているこのブログ内の記事