たつをの ChangeLog : 2005-08-23
Yahoo!ミュージック - サウンドステーション
<http://station.music.yahoo.co.jp/>
無料の音楽ストリーム配信。とりあえずブラウザがあればOK。
ひたすら音楽だけ流れるのでBGMとして手軽。
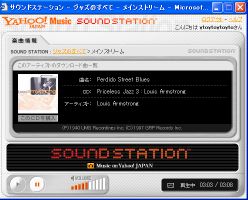
制約として以下の事項が。
<http://help.yahoo.co.jp/help/jp/music/ss/b01.html>
- 最初に広告を30秒。5曲再生すると再び広告。
- 10曲再生すると停止。
BGMとしては不便な面もあるけど、「再生停止=休憩するタイミング」のようにリマインダ的な用途としても使えるかも。
ref. <http://sho.tdiary.net/20050823.html#p01>
<http://station.music.yahoo.co.jp/>
無料の音楽ストリーム配信。とりあえずブラウザがあればOK。
ひたすら音楽だけ流れるのでBGMとして手軽。
制約として以下の事項が。
<http://help.yahoo.co.jp/help/jp/music/ss/b01.html>
- 最初に広告を30秒。5曲再生すると再び広告。
- 10曲再生すると停止。
BGMとしては不便な面もあるけど、「再生停止=休憩するタイミング」のようにリマインダ的な用途としても使えるかも。
ref. <http://sho.tdiary.net/20050823.html#p01>
ReadMe! JAPAN[2004-04-28-2] というサービスに参加しています。
各ページにカウントアイコンを貼り付けると、自分のサイトの登録情報のページ(私のは <http://s.readmej.com/m/yto/nais.to>)で、アクセス数上位10ページが表示されます(一日一回更新)。
この中から自分のBlogの個別記事ページだけ抜き出して、アクセス数による「自blogの注目記事リスト」を生成する簡単なスクリプトを作りました。
ref. はてなブックマークによる自blogの注目記事リスト[2005-08-10-3]
■設置例

■ソース
超 ad hoc です。解説は後述。
■仕組みについて解説
登録情報ページ(例:<http://s.readmej.com/m/yto/nais.to>)では、以下のようにアクセス数上位10ページ分がtableで表示されています。
私のBlogの記事別ページの URL は「\d{4}-\d\d-\d\d-\d+.html」という正規表現で絞り込めますので、それで取り出します。
そして、それぞれの URL にアクセスし、そのページの title も取り出します(chalow なので cl.itemlist を使えば楽ですが、ちょっとだけ汎用化)。
あとは「くっつき化」(JavaScript ファイル化) するだけです。
負荷を考えて、crontab で一日一回実行するようにしました。
各ページにカウントアイコンを貼り付けると、自分のサイトの登録情報のページ(私のは <http://s.readmej.com/m/yto/nais.to>)で、アクセス数上位10ページが表示されます(一日一回更新)。
この中から自分のBlogの個別記事ページだけ抜き出して、アクセス数による「自blogの注目記事リスト」を生成する簡単なスクリプトを作りました。
ref. はてなブックマークによる自blogの注目記事リスト[2005-08-10-3]
■設置例
■ソース
超 ad hoc です。解説は後述。
#!/usr/bin/perl -w
# This is free software with ABSOLUTELY NO WARRANTY.
# 無償・無保証・著作権放棄 (see http://lifehacks.ta2o.net/byebye-copyright.html)
#
# Web ページへのくっつけ方 (例):
# <div class="rssbox">
# <script language="JavaScript" src="readme.js"></script>
# </div>
use strict;
my $output_fn = shift; # JS出力先ファイル名
### ReadMe! の登録情報ページへのアクセス(事情によりwget使用)
`/usr/bin/wget -O /var/tmp/a -q http://s.readmej.com/m/yto/nais.to`; ###ここ変更!###
open(F, "/var/tmp/a") or die;
my $readme_cont = join('',<F>);
close F;
### ランキング情報取り出し
my @plist;
while ($readme_cont =~
m|<TR>\n<TD>(http.+?)</TD>\n<TD ALIGN="right">(\d+)</TD>\n</TR>|gsm) {
my ($u, $c) = ($1, $2);
next if ($u !~ /\d{4}-\d\d-\d\d-\d+.html/); ###ここ変更!###
push @plist, {'url'=>$u, 'count'=>$c};
}
die if (@plist == 0);
### 記事ページからの title 情報の取り出し
use LWP::Simple;
foreach (@plist) {
my $u = $_->{url};
my $c;
($c = get($u)) or die "Can't get $u\n";
($_->{title}) = ($c =~ m|<title>(.+?)</title>|smi);
}
### JavaScript ファイル作成
my $str = "<ul>";
foreach (@plist) {
$_->{title} =~ s/\'//g;
$str .= qq(<li><a href="$_->{url}">$_->{title}</a> ($_->{count}));
}
$str .= "</ul>";
$str =~ s/\n//g;
open(F, "> $output_fn") or die "Can't open $output_fn : $!\n";
print F "document.writeln('$str');\n";
close(F);
(「無償・無保証・著作権放棄」<http://lifehacks.ta2o.net/byebye-copyright.html>)■仕組みについて解説
登録情報ページ(例:<http://s.readmej.com/m/yto/nais.to>)では、以下のようにアクセス数上位10ページ分がtableで表示されています。
私のBlogの記事別ページの URL は「\d{4}-\d\d-\d\d-\d+.html」という正規表現で絞り込めますので、それで取り出します。
そして、それぞれの URL にアクセスし、そのページの title も取り出します(chalow なので cl.itemlist を使えば楽ですが、ちょっとだけ汎用化)。
あとは「くっつき化」(JavaScript ファイル化) するだけです。
負荷を考えて、crontab で一日一回実行するようにしました。
この記事に言及しているこのブログ内の記事
たつをの ChangeLog
Powered by chalow