21 件 見つかりました。
Python で Perl の Search::Dict[2013-08-01-1] 相当のライブラリないかなー、と思いつつ過ごす日々です。
最近、二分探索 (binary search) のロジックを Python で書いてソート済みテキストを検索するというコードをネットで見つけました。
確実に遅くなるだろうけどとりあえず実用性を調べてみることに。
まずこちらのスクリプトを試しました。
しかしうまく検索できないこと多々あり。
"/usr/share/dict/words" の各ワードをASCII順序でソート済みの "/usr/share/dict/words" から検索して取り出す実験を行ったところ約 27% (171318/235970) の単語にヒットしませんでした。
コード中の「途中の行は読み捨てる」とコメントされてる箇所に問題がありそうです。
捨てちゃいけないものが混じっているのかと。
実験コマンド:
1の「lookコマンドのpythonによる実装」で参考として挙げられていたこちらも調べてみました。
こちらはというと、二分探索の各ステップで行頭までファイルポインタを移動するときのこちらのコードに少々問題が。
一行が長いとき(例えば 5000 バイトなど)に無茶苦茶遅くなるのです。
C言語とかなら問題ないのですが、スクリプトレベルでやるには厳しいですね。
ということで、結局既存のものをそのまま利用するのはあきらめて、前述の1と2のコードをベースに書き直しました。
(なお、1でやった実験と同じ実験をしたら単語ヒット率 100% でした)
ポイントは行頭までのファイルポインタ移動 (go_to_line_top()) に readline() を使ったこと。
readline() はコンパイルされた実装なので速いです。
ファイルポインタ行頭移動ロジック:
先日の実験で最速だった look.pl (Search::Dict 使用) と比べると 6倍くらい時間がかかりました(buffer_size を小さくすると縮まります)。
ここらへんがスクリプト言語ロジック記述の限界かなあ。
look コマンドの Perl モジュールである Search::Dict。これに相当の Python ライブラリが見つからないので、Python スクリプトで実現する方法の実用性を調べました。
その結果、Search::Dict 版には及ばないもののそこそこの速さでした。
このくらいの速度差ならば普段の私のタスクでは実用上問題ないレベルかも。
Perl が使えないときとか、Python プログラムの中から使いたいときとか。
とはいえ、やはり Perl の Search::Dict 相当の Python ライブラリ (C extention?) を切望します!
情報あったら教えてくださいませ。
最近、二分探索 (binary search) のロジックを Python で書いてソート済みテキストを検索するというコードをネットで見つけました。
確実に遅くなるだろうけどとりあえず実用性を調べてみることに。
1
まずこちらのスクリプトを試しました。
しかしうまく検索できないこと多々あり。
"/usr/share/dict/words" の各ワードをASCII順序でソート済みの "/usr/share/dict/words" から検索して取り出す実験を行ったところ約 27% (171318/235970) の単語にヒットしませんでした。
コード中の「途中の行は読み捨てる」とコメントされてる箇所に問題がありそうです。
捨てちゃいけないものが混じっているのかと。
実験コマンド:
cat WORDS-ASCII_SORTED | xargs -L1 ./look.py > res
2
1の「lookコマンドのpythonによる実装」で参考として挙げられていたこちらも調べてみました。
こちらはというと、二分探索の各ステップで行頭までファイルポインタを移動するときのこちらのコードに少々問題が。
while p >= 0:
self.f.seek(p)
if self.f.read(1) == '\n': break
p -= 1
一行が長いとき(例えば 5000 バイトなど)に無茶苦茶遅くなるのです。
C言語とかなら問題ないのですが、スクリプトレベルでやるには厳しいですね。
3
ということで、結局既存のものをそのまま利用するのはあきらめて、前述の1と2のコードをベースに書き直しました。
(なお、1でやった実験と同じ実験をしたら単語ヒット率 100% でした)
ポイントは行頭までのファイルポインタ移動 (go_to_line_top()) に readline() を使ったこと。
readline() はコンパイルされた実装なので速いです。
ファイルポインタ行頭移動ロジック:
- 事前準備: そのファイルに含まれる行の最大長+αを buffer_size にセット
- 現在のファイルポインタから buffer_size 分前方に seek()
- そこから readline() を繰り返して最終行を取得
- 最終行の長さ分前方に seek ()
- 行頭にファイルポインタが移動できた!
先日の実験で最速だった look.pl (Search::Dict 使用) と比べると 6倍くらい時間がかかりました(buffer_size を小さくすると縮まります)。
ここらへんがスクリプト言語ロジック記述の限界かなあ。
- 手軽に使える look コマンドの速度比較[2023-09-03-1]
- 先日の実験
- 今回の looks.py での結果 (buffer_size=10000) も追記しました
おわりに
look コマンドの Perl モジュールである Search::Dict。これに相当の Python ライブラリが見つからないので、Python スクリプトで実現する方法の実用性を調べました。
その結果、Search::Dict 版には及ばないもののそこそこの速さでした。
このくらいの速度差ならば普段の私のタスクでは実用上問題ないレベルかも。
Perl が使えないときとか、Python プログラムの中から使いたいときとか。
とはいえ、やはり Perl の Search::Dict 相当の Python ライブラリ (C extention?) を切望します!
情報あったら教えてくださいませ。
この記事に言及しているこのブログ内の記事
【Python】セイウチ演算子 (Walrus operator)
2022-09-11-1
[Python][Programming]
セイウチ演算子 (Walrus operator)。
代入のときに ":=" を使うと、その変数がその後スコープ内で使える。
Python 3.8 から使えるそうな。
こんな感じ:
Perl だと:
代入のときに ":=" を使うと、その変数がその後スコープ内で使える。
Python 3.8 から使えるそうな。
こんな感じ:
### Python
import random
if a := int(random.random() * 2):
print(f'true [{a}]')
else:
print(f'false [{a}]')
Perl だと:
### Perl
use strict;
use warnings;
if (my $a = int(rand(2))) {
print "true [$a]\n";
} else {
print "false [$a]\n";
}
# 右辺によっては「代入と比較を間違ってませんか」的な warning が出る
if (my $a = 1) {
print "true [$a]\n";
} else {
print "false [$a]\n";
}
CSV ファイルで、テキストのカラムにカンマが入っているんだけど、そのカラムがダブルクォート文字で囲まれていないときの対処法について。
ときどきそういうデータがあるのです。
適当なその場しのぎスクリプトで CSV 出力した結果とか。
で、それをなんとかして使わないといけない場面もあるのです。
怒ってないです。
例えば、全部で10カラムのCSV。
第4カラムにテキスト。
CSV だからカンマ区切りなんだけど、テキストにカンマが含まれてる場合あり。
しかもダブルクォートで囲まれていない。
区切りのカンマと区別つかなくて困る。
こういうときは、前から3カラム(=4-1)、後ろから6カラム(=10-4)を除いた残りすべてを一つのテキストとする作戦で。
Perl で書くとこんな感じ。
splice 関数を使ったバージョン。
Perl の split 関数の第3引数の "-1" についてはこちらを参照。
Python で書くとこんな感じ。
右側から分割してくれる rsplit 関数がこの用途に便利。
カンマ入りテキストカラムが複数ある場合はちょっと難しい。めんどくさいのであきらめましょう。桁区切りカンマ入りの数値がクォート無しで複数カラムあるとかも。
あと、上のスクリプトではテキストにダブルクォートが含まれててエスケープされてない場合は考慮してません。join で "\t" を使って TSV にしとくのが良いかと。テキストに "\t" がない前提で。
ときどきそういうデータがあるのです。
適当なその場しのぎスクリプトで CSV 出力した結果とか。
で、それをなんとかして使わないといけない場面もあるのです。
怒ってないです。
例えば、全部で10カラムのCSV。
第4カラムにテキスト。
0,2,0,こんにちは,50,0,0,0,0,0 1,1,1,さようなら,0,0,0,0,0,0
CSV だからカンマ区切りなんだけど、テキストにカンマが含まれてる場合あり。
しかもダブルクォートで囲まれていない。
区切りのカンマと区別つかなくて困る。
理想: 1,1,0,"ああ,いい,ううう。",21,0,0,0,0,0 0,2,0,"あれれれ,",50,0,0,0,0,0 現実: 1,1,0,ああ,いい,ううう。,21,0,0,0,0,0 0,2,0,あれれれ,,50,0,0,0,0,0
こういうときは、前から3カラム(=4-1)、後ろから6カラム(=10-4)を除いた残りすべてを一つのテキストとする作戦で。
1,1,0,ああ,いい,ううう。,21,0,0,0,0,0 ↓ カンマで分割してリストにする 1 1 0 ああ いい ううう。 21 0 0 0 0 0 ↓ 前と後ろのカラムを取る [1 1 0] ああ いい ううう。 [21 0 0 0 0 0] ↓ ああ いい ううう。 ↓ 残りをカンマで繋ぎ直し、ダブルクォートで囲む "ああ,いい,ううう。" ↓ さっき取った、前と後ろのカラムと合わせて最終的な CSV にする 1,1,0,"ああ,いい,ううう。",21,0,0,0,0,0
Perl
Perl で書くとこんな感じ。
my $IX = 4; # 4番目のカラムがカンマ入りテキスト
my $N = 10; # 全部で10カラム
while (<>) {
chomp; # 末尾の改行削除
my @F = split(",", $_, -1); # 読み込んだ CSV 行をカンマで切ってリストへ
my @pre = @F[0..($IX-2)]; # 前から IX-1 個分のカラム
my @post = @F[$#F-($N-$IX-1)..$#F]; # 後ろから N-IX 個分のカラム
my $text = join(",", @F[($IX-1)..($#F-($N-$IX))]); # カンマ入りテキスト
print join(",", @pre, "\"$text\"", @post)."\n"; # CSV に戻す
}
splice 関数を使ったバージョン。
my $IX = 4; # 4番目のカラムがカンマ入りテキスト
my $N = 4; # 全部で10カラム
while (<>) {
chomp; # 末尾の改行削除
my @F = split(",", $_, -1); # 読み込んだ CSV 行をカンマで切ってリストへ
my @ts = join(",", splice(@F, $IX-1, (@F-$N) + 1)); # テキスト部分の抜き出し
splice(@F, $IX-1, 0, qq(").join(",", @ts).qq(")); # ""をつけて戻す
print join(",", @F)."\n"; # CSV に戻す
}
Perl の split 関数の第3引数の "-1" についてはこちらを参照。
Python
Python で書くとこんな感じ。
右側から分割してくれる rsplit 関数がこの用途に便利。
ID = 4
N = 10
with open('sample.csv') as f:
for line in f.read().splitlines():
pre = line.split(",", ID - 1)
post = pre[-1].rsplit(",", N - ID)
l = pre[:-1]
l.append('"' + post[0] + '"')
l.extend(post[1:])
print(",".join(l))
1,1,0,ああ,いい,ううう。,21,0,0,0,0,0 ↓ 最初の split で前から4分割(3箇所で切断) 1 / 1 / 0 / ああ,いい,ううう。,21,0,0,0,0,0 ↓ 一番右の塊を次の rsplit で後ろから7分割(6箇所で切断)。 ああ,いい,ううう。 / 21 / 0 / 0 / 0 / 0 / 0 ↓ 1 / 1 / 0 / ああ,いい,ううう。 / 21 / 0 / 0 / 0 / 0 / 0 ↓ 1,1,0,"ああ,いい,ううう。",21,0,0,0,0,0
おわりに
カンマ入りテキストカラムが複数ある場合はちょっと難しい。めんどくさいのであきらめましょう。桁区切りカンマ入りの数値がクォート無しで複数カラムあるとかも。
あと、上のスクリプトではテキストにダブルクォートが含まれててエスケープされてない場合は考慮してません。join で "\t" を使って TSV にしとくのが良いかと。テキストに "\t" がない前提で。
MongoDB を試してみる
2020-10-24-1
[Programming][Python]
今更ながら、MongoDB を macOS と CentOS7 で試してみた。ざっくりとだけど一通り流れは理解できた。
目的の一つは、ある商品群の価格変化を記録していくこと。Keepa みたいなイメージ。私がよくやっている「TSVファイルに追加していく単純な方式」と比べ、速度や使い勝手がどうなのかは、サーバで運用しながら調べていく予定。
これらを参考に。
起動:
MongoDB の current version は 4.4。
ここの手順に従う。
まず、"/etc/yum.repos.d/mongodb-org-4.4.repo" を作り、それから yum を実行。
起動:
目的の一つは、ある商品群の価格変化を記録していくこと。Keepa みたいなイメージ。私がよくやっている「TSVファイルに追加していく単純な方式」と比べ、速度や使い勝手がどうなのかは、サーバで運用しながら調べていく予定。
macOS へのインストール
環境: MacBook Pro (13-inch, 2017), macOS 10.15.7。これらを参考に。
今はできない。代わりの方法。brew install mongodb
brew tap mongodb/brew brew install mongodb-community cat /usr/local/etc/mongod.conf systemLog: destination: file path: /usr/local/var/log/mongodb/mongo.log logAppend: true storage: dbPath: /usr/local/var/mongodb net: bindIp: 127.0.0.1
起動:
brew services start mongodb-community
CentOS7 へのインストール
環境: さくらVPS, CentOS 7。MongoDB の current version は 4.4。
ここの手順に従う。
まず、"/etc/yum.repos.d/mongodb-org-4.4.repo" を作り、それから yum を実行。
sudo yum install -y mongodb-org
起動:
sudo systemctl start mongod
動作の確認
mongo
use test
show dbs
db.stats()
# db.createCollection('hello')
show collections
db.hello.stats()
db.hello.insert({'uid':123, 'test':'World'})
db.hello.insert({'uid':"oreore", 'text':'This is a pen.'})
db.hello.insert({'uid':"you", 'text':'Today is ...'})
db.hello.find()
db.hello.findOne()
db.hello.findOne()["uid"]
var r = db.hello.find()
while (r.hasNext()) printjson(r.next())
quit()
バックアップ&リストア
mongodump -d test mongo use test db.hello.drop() db.dropDatabase() show dbs quit() mongorestore ./dump
監視
mongotop mongostat
取り出し
db.hello.find({}, {uid: 1, text: 1, _id: 0})
db.hello.find({$or: [{'uid':123}, {'uid':"you"}]}, {uid: 1, text: 1, _id: 0})
db.hello.find({$or: [{'uid':123}, {'uid':"you"}, {'uid':"oreore"}]}, {ud: 1, text: 1, _id: 0})
db.hello.find({$or: [{'uid':123}, {'uid':"you"}, {'uid':"NO"}]}, {uid: 1, text: 1, _id: 0})
更新
db.hello.update({"uid" : "you"}, {$set : {"text":"こんにちは"}})
db.hello.insert({'uid':"me", 'hist':[{'ymd':20201020,'val':12}]})
db.hello.update({'uid':"me"}, {$push:{'hist':{'ymd':20201024,'val':38}}})
db.hello.update({'uid':"me"}, {$set:{'last-update':ISODate("2020-10-24T12:55:15")}})
Python
インストール:テストスクリプト:pip install pymongo
from pymongo import MongoClient
import datetime
dt_now = datetime.datetime.now()
client = MongoClient('localhost',27017)
db = client.test
col = db.hello
for i in col.find():
print(i)
col.update_one({'uid':"me"}, {
'$push':{'hist':{'ymd':dt_now,'val':189}},
'$set':{'last-update':dt_now}
})
print(col.find_one({'uid':"me"}))
参考
5月頭に書いた記事「東京都の新型コロナウイルスでの年代別死亡者数が公表されたのでグラフを作ってみた[2020-05-02-1]」の続きです。
6月までの年代別死亡者数が出ていたのでグラフをアップデートしました。
python, jupyter notebook, pandas, matplotlib を使っています。
10万人あたり陽性患者数と死亡者数を年代別に表示したもの。

比較のために前回のグラフもあげておきます。

陽性患者はご存知の通り、若い世代に増えています。
一方、死亡者は高齢者に多いのですが、前回と比べると、高齢者の死亡率がかなり上がっています。
こちらは個別にいろいろ表示してみたもの。
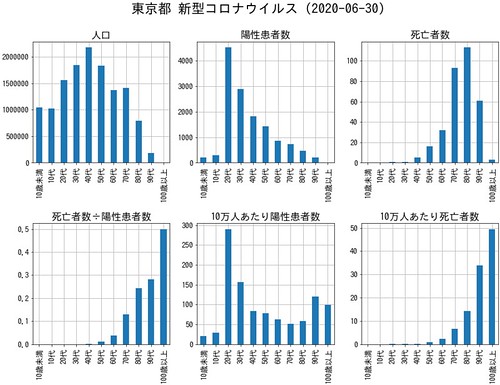
左下の死亡者数÷陽性患者数(≒死亡率)。
件数は少ないのですが100歳以上は50%です。
80・90代は30%近くまで上昇。
前回は10%代でした。
高齢者には致命的なものだということが納得できます。
ソースコードは前回のもの(Jupyter Notebook の HTML)とほぼ同じです。
年代別死亡者数の部分はもちろん更新しています。
6月までの年代別死亡者数が出ていたのでグラフをアップデートしました。
python, jupyter notebook, pandas, matplotlib を使っています。
- 6月までの死亡者 都が詳細公表|NHK 首都圏のニュース
亡くなった人のうち、20代は1人で全体に占める割合は0.3%、30代は1人で0.3%、40代は5人で1.5%、50代は16人で4.9%、60代は32人で9.9%、70代は93人で28.6%、80代は113人で34.8%、90代は61人で18.8%、100歳以上は3人で0.9%でした。
10万人あたり陽性患者数と死亡者数を年代別に表示したもの。
比較のために前回のグラフもあげておきます。
陽性患者はご存知の通り、若い世代に増えています。
一方、死亡者は高齢者に多いのですが、前回と比べると、高齢者の死亡率がかなり上がっています。
こちらは個別にいろいろ表示してみたもの。
左下の死亡者数÷陽性患者数(≒死亡率)。
件数は少ないのですが100歳以上は50%です。
80・90代は30%近くまで上昇。
前回は10%代でした。
高齢者には致命的なものだということが納得できます。
コード
ソースコードは前回のもの(Jupyter Notebook の HTML)とほぼ同じです。
年代別死亡者数の部分はもちろん更新しています。
- 前回(2020-05-01)
ddf['死亡者数'] = (0,0,0,0,1,9,18,40,38,16,0)
- 今回(2020-06-30)
ddf['死亡者数'] = (0,0,1,1,5,16,32,93,113,61,3)
過去記事
Powered by chalow