31 件 見つかりました。
グループ分けを複数回やるときになるべく同じ人とかぶらないように振り分ける、というのはよくある課題ですが、それを解決するツールを作りました (HTML + JavaScript)。車輪の再発明とか知らん。

「作りました」とは言っていますが、プログラムのコードはすべて生成AI(ChatGPT)に書いてもらいました。私は仕様書(兼プロンプト)を書いただけで、ChatGPTに仕様書テキスト貼り付けて「これ作って!」と頼む係です(今後このパターンで作成・公開することが増えそうです)。
この手のウェブツール作成は生成AIの得意分野ですね。一手目からかなり思い描いた通りのものが出てきて、未来を感じます。「こういうツールを作りたい」という要望を持つのはまだ人間側の特権(?)みたいなものですので、要望をしっかりと仕様(プロンプト)に落とし込むことが出来さえすればAIとうまく共存できそうな気がしています。当面の間は。
というありきたりな生成AI感想は置いておいて、振り分けロジックの話。結局、目から鱗が落ちるようなトンチ的な解決方法はなくて、スタンダードなやり方に落ち着きました。これまでの回に誰と誰が一緒のグループになったかという共起情報を振り分けのときの使う作戦です。
データの持ち方は、参加者それぞれが何回目にどのグループに割り振られたかの履歴を持ち回るという方法。"#1A" は1回目にグループAに振り分けれらたこと、"#1A#2B#3C" は1回目はグループA、2回目はグループB、3回目はグループCに振り分けられたことを意味する履歴です。"天下一太郎#1A#2B#3C" のように参加者名の末尾にこの履歴を繋げて、それ自体をマスターデータとしています。必要な情報はすべて人目につくようにしています。
そんなわけで、この履歴付き参加者一覧をテキストでコピペすれば、セーブ&ロードになります。前回の続きから(例えば第5回から)グループ分けの再開ができるのです。
途中参加の人は参加者リストの末尾に履歴なしで名前を足すだけ。途中でいなくなる人はその名前を履歴ごと削除するだけ。シンプルです。
グループ振り分けがうまくできたかの評価基準として「またかよ数(MK)」「またかよ平均(MA)」というのを導入しています。これらは共起 (cooccurence) 関連の数値でして、キャッチーにそう呼んでいるだけです。
なお、ツール名はChatGPTに考えてもらいました。他のネーミング候補としては「一期一会シャッフル」「またかよ防止くん」「グループシャッフル最適化ツール」「もう会わないグルーピング」などがありました(すべてChatGPTによる)。
- 低かぶり複数回グルーピングツール「バラすくん」
https://yto.github.io/barasu/barasukun.html
「作りました」とは言っていますが、プログラムのコードはすべて生成AI(ChatGPT)に書いてもらいました。私は仕様書(兼プロンプト)を書いただけで、ChatGPTに仕様書テキスト貼り付けて「これ作って!」と頼む係です(今後このパターンで作成・公開することが増えそうです)。
この手のウェブツール作成は生成AIの得意分野ですね。一手目からかなり思い描いた通りのものが出てきて、未来を感じます。「こういうツールを作りたい」という要望を持つのはまだ人間側の特権(?)みたいなものですので、要望をしっかりと仕様(プロンプト)に落とし込むことが出来さえすればAIとうまく共存できそうな気がしています。当面の間は。
というありきたりな生成AI感想は置いておいて、振り分けロジックの話。結局、目から鱗が落ちるようなトンチ的な解決方法はなくて、スタンダードなやり方に落ち着きました。これまでの回に誰と誰が一緒のグループになったかという共起情報を振り分けのときの使う作戦です。
データの持ち方は、参加者それぞれが何回目にどのグループに割り振られたかの履歴を持ち回るという方法。"#1A" は1回目にグループAに振り分けれらたこと、"#1A#2B#3C" は1回目はグループA、2回目はグループB、3回目はグループCに振り分けられたことを意味する履歴です。"天下一太郎#1A#2B#3C" のように参加者名の末尾にこの履歴を繋げて、それ自体をマスターデータとしています。必要な情報はすべて人目につくようにしています。
そんなわけで、この履歴付き参加者一覧をテキストでコピペすれば、セーブ&ロードになります。前回の続きから(例えば第5回から)グループ分けの再開ができるのです。
途中参加の人は参加者リストの末尾に履歴なしで名前を足すだけ。途中でいなくなる人はその名前を履歴ごと削除するだけ。シンプルです。
グループ振り分けがうまくできたかの評価基準として「またかよ数(MK)」「またかよ平均(MA)」というのを導入しています。これらは共起 (cooccurence) 関連の数値でして、キャッチーにそう呼んでいるだけです。
- 「またかよ数」は参加者それぞれがグループ振り分け後に「またこの人と同じグループかよ!」と思う回数の合計です。「またAさんと一緒かよ、Bさんもかよ、Bさんは3回目だよ」という場合はこれまでにAさんは1回、Bさんは2回一緒だったので「またかよ数」は3となります。
- 「またかよ平均」はそのグループの全メンバーの「またかよ数」の平均で、そのグループにうずまく「またかよ!」の強さを表しています。
なお、ツール名はChatGPTに考えてもらいました。他のネーミング候補としては「一期一会シャッフル」「またかよ防止くん」「グループシャッフル最適化ツール」「もう会わないグルーピング」などがありました(すべてChatGPTによる)。
Tekitof はウェブページ上で表示要素のフィルターやソートを行う JavaScript ライブラリです。Tekitof は「テキトフ」と読みます。適当フィルター、略してテキトフ、です。
github でリリースしました。
ソースをコピペすればすぐに使えるサンプルページも用意しました。

こういうライブラリってもちろん既存のがいろいろあるのですが、どれも大袈裟な感じで使いづらく感じていました。ちょこっとコードいじってカスタマイズしたいのに混み入りすぎて無理、とか。なので、自分が使いやすいミニマムなやつを作りました。車輪の再発明です。というかむしろ自分専用車輪の大発明です。
他と比べて特に優れた点はないのですが、特徴をいくつか。
2年ほど前から Kindle セール情報サイト「キンセリ」で導入しています。というか、キンセリで使うために作った、というのが正しいですね。
例えば、キンセリのトップページの開催中のセール一覧で、開催中のセールをジャンルや出版社で絞ったり、開始・終了日や人気度でソートしたりする部分。また、個別 Kindle セールをまとめたページ(例)でのレーベルや読み放題などでの絞り込み、価格や割引率や配信日でのソートなど。その他、キンセリ内のあちこちで使っています。
今後キンセリ以外(例えばブラウザ拡張機能とか)でも使っていこうと思って、こうして公開してみた次第です。よかったら見てみてください。
以上です。
github でリリースしました。
ソースをコピペすればすぐに使えるサンプルページも用意しました。
こういうライブラリってもちろん既存のがいろいろあるのですが、どれも大袈裟な感じで使いづらく感じていました。ちょこっとコードいじってカスタマイズしたいのに混み入りすぎて無理、とか。なので、自分が使いやすいミニマムなやつを作りました。車輪の再発明です。というかむしろ自分専用車輪の大発明です。
他と比べて特に優れた点はないのですが、特徴をいくつか。
- 150行くらいでコンパクト
- 内部で何をやっているのかの見通しが良い
- 他のライブラリへの依存はゼロ
- 複数キーワードの AND/OR 条件もサポート
- フィルターの重ねがけが可能
- 絞り込み結果にさらに別条件での絞り込みをかけられる
2年ほど前から Kindle セール情報サイト「キンセリ」で導入しています。というか、キンセリで使うために作った、というのが正しいですね。
例えば、キンセリのトップページの開催中のセール一覧で、開催中のセールをジャンルや出版社で絞ったり、開始・終了日や人気度でソートしたりする部分。また、個別 Kindle セールをまとめたページ(例)でのレーベルや読み放題などでの絞り込み、価格や割引率や配信日でのソートなど。その他、キンセリ内のあちこちで使っています。
今後キンセリ以外(例えばブラウザ拡張機能とか)でも使っていこうと思って、こうして公開してみた次第です。よかったら見てみてください。
以上です。
この記事に言及しているこのブログ内の記事
手元でのちょっとした用途で類似テキスト検索をやりたいのですが、
Linux環境であれこれインストールしなくても動かせて、
気ままにカスタマイズできる気が利いたやつがなかったので、
改めて作ってみました。
過去に何度も書いたことのあるプログラムなので目新しさはありませんが。
(「車輪の再発明を気にしない」が私の行動指針です!)

私の母プログラミング言語(母語)である Perl で書いています。
標準ライブラリしか使っていないので、
Perl さえインストールすればどこでも動くはずです。
転置インデックス(+リランキング)用のスクリプトと、リランキングだけするスクリプトがあります。
リランキング時のスコア計算方法は README.md を参照されたし。
Linux環境であれこれインストールしなくても動かせて、
気ままにカスタマイズできる気が利いたやつがなかったので、
改めて作ってみました。
過去に何度も書いたことのあるプログラムなので目新しさはありませんが。
(「車輪の再発明を気にしない」が私の行動指針です!)
- yto/simpii: Simple Inverted Index Search
https://github.com/yto/simpii
私の母プログラミング言語(母語)である Perl で書いています。
標準ライブラリしか使っていないので、
Perl さえインストールすればどこでも動くはずです。
転置インデックス(+リランキング)用のスクリプトと、リランキングだけするスクリプトがあります。
リランキング時のスコア計算方法は README.md を参照されたし。
関連記事
- 転置インデックスによる検索システムを作ってみよう![2007-11-26-5]
- simpii は、14年前に書いたこれの改訂版みたいな位置づけです。
- ソート済みのテキストファイルを二分探索で高速検索する Perl 標準モジュール「Search::Dict」[2013-08-01-1]
- インデックス検索部分はこれを使っています。
- Algorithm::Diff で類似文字列検索[2008-04-22-3]
この記事に言及しているこのブログ内の記事
cut と fold のUTF8対応版
2018-12-11-1
[Perl][Programming]
素の cut (-c) と fold コマンドは UTF-8 の文字列に対して途中で切っちゃうこともあって文字化けして困る。cut と fold のUTF8対応版が欲しい。
流石にネットのどこかにあるだろうと思って探してみたんだけど、探し方が悪かったのかすぐには見つからず。3分くらいがんばって調べてみたけど、こりゃ作った方が早いな、ということで車輪の再発明。
ざっくりと perl で書いています。
(追記190325: fold8 の空行が出ないバグを修正)
流石にネットのどこかにあるだろうと思って探してみたんだけど、探し方が悪かったのかすぐには見つからず。3分くらいがんばって調べてみたけど、こりゃ作った方が早いな、ということで車輪の再発明。
ざっくりと perl で書いています。
cut8 - UTF8対応cut
"-c" オプションのみ。
#!/usr/bin/perl
use strict;
use warnings;
use Getopt::Long;
use open ':utf8';
binmode STDIN, ":utf8";
binmode STDOUT, ":utf8";
my $cps_str = ""; # character positions
GetOptions("c=s" => \$cps_str);
my @cps = sort {_toint($a) <=> _toint($b)} split(/,/, $cps_str);
sub _toint {$_[0] =~ /^(\d+)/; $1}
while (<>) {
chomp;
my @c = split(//, $_);
foreach my $cp (@cps) {
if ($cp =~ /^(\d+)-(\d+)$/) {
print map {defined $_ ? $_ : ""} @c[($1-1)..($2-1)];
} else {
print $c[$cp-1]||"";
}
}
print "\n";
}
echo "あいうえおかきくけこ" | cut8 -c 1-3,7-9 あいうきくけ
fold8 - UTF8対応fold
"-w" オプションのみ。
#!/usr/bin/perl
use strict;
use warnings;
use Getopt::Long;
use open ':utf8';
binmode STDIN, ":utf8";
binmode STDOUT, ":utf8";
my $width = 80;
GetOptions("width=s" => \$width);
while (<>) {
chomp;
my $line = $_;
if (length($line)) {
while ($line =~ s/^(.{$width})//) {
print "$1\n";
}
next if not length($line);
}
print "$line\n";
}
echo "あいうえおかきくけこ" | fold8 -w 4 あいうえ おかきく けこ
(追記190325: fold8 の空行が出ないバグを修正)
アマゾンの画像を自由自在にbufferに取り込みたい
2018-10-12-1
[Programming][Affiliate]
自分用メモ。
アマゾンのドメインのどんな画像URLでもそのままbufferで扱えるようにしたい。
うまく扱えない画像は以下のものがある。
いちいちローカルにdownloadしてからbufferにuploadするの面倒。
なので、それ用のミニマムなツールを作った。
結局、1ページのみのCMSみたいなものになった。
こういう件では、車輪の再発明は気にしない。
自分で作った方が速いし、細かい調整も楽だし。
アマゾンのドメインのどんな画像URLでもそのままbufferで扱えるようにしたい。
うまく扱えない画像は以下のものがある。
- 一部のバナー画像
- URL に「+」が含まれている画像(主に書影)
いちいちローカルにdownloadしてからbufferにuploadするの面倒。
なので、それ用のミニマムなツールを作った。
結局、1ページのみのCMSみたいなものになった。
こういう件では、車輪の再発明は気にしない。
自分で作った方が速いし、細かい調整も楽だし。
- 課題
- アマゾンのURLをbuffer(の入力フォーム)に貼るとき、画像が取り込めないことがある
- 画像URL (.../*.jpg など) を直接bufferに貼っても画像は取り込めない
- なんとかしたい
- 解決策
- 誰でもアクセスできるページ(permalinkあり)を自由にHTML編集できる簡単で安全なCMS
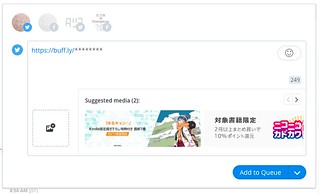
- imgタグで画像URLを貼り保存ののち、そのページのURLをbufferに入力
- bufferに画像を取り込んだら用済み
- 実装
- 「TextAreaWiki」をベースに (ref. [2018-10-09-1])
- Editor (CGI) でユーザがHTMLを編集する
- Editor は「https + Basic認証」なところに置かれるので安全
- Editor はpermalinkに対応するディレクトリにHTMLファイルを出力
- キャッシュ対策で、permalink URLの末尾にUTCを足す (例:.../cms/?1234567890)
- 実行画面キャプチャ
- Editor (https://.../opc.cgi)
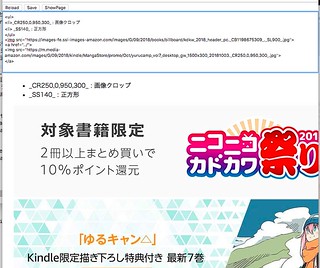
- 出力先 permalink (https://.../cms/?1234567890)
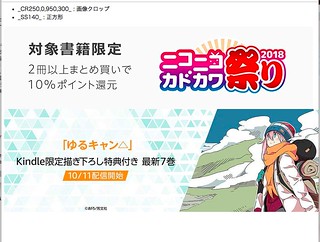
- permalink を buffer に貼った様子(画像を選択したのち、本命テキストに置き換える)
- Editor (https://.../opc.cgi)
- Tips
- 横長・縦長すぎるバナーはbufferに読み込まれないので、画像URLで「CR」を用いてクロップする
- 例: yurucamp_vol7_desktop_gw_1500x300_20181003._CR250,0,950,300_.jpg
- (うまくいかないこともある)
- 参考: Amazon商品画像のカスタマイズ(理論編) - Shiz Labs
- URL に「+」が含まれている書影画像はASIN入りの URL に変換して使用する
- bad: //images-fe.ssl-images-amazon.com/images/I/51mWcqy%2BipL.jpg
- ok: //images-fe.ssl-images-amazon.com/images/P/B00UAAK07S.09.jpg
- 参考: HTTPS時代のURLパラメータによるAmazon商品画像加工[2018-05-28-1]
- 横長・縦長すぎるバナーはbufferに読み込まれないので、画像URLで「CR」を用いてクロップする
Powered by chalow