全ツイート履歴「tweets.csv」を軽く集計してみる
2013-03-22-4
[Programming]
全ツイート履歴が取得できるようになったので、取ってきて軽く分析(というほどでもないが)してみた。
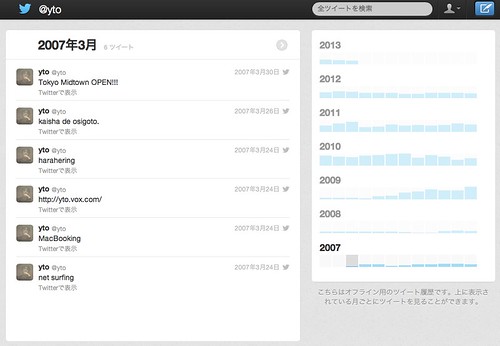
(↑一番最初の発言は2007年3月24日)
「全ツイート履歴」の詳細は下記の記事を参照されたし:
- 日本の皆さんにも「全ツイート履歴」が使えるようになりました (Twitterブログ)
http://blog.jp.twitter.com/2013/03/blog-post_22.html
ダウンロードした中に含まれているファイル「tweets.csv」に全ツイートが入っている。
文字コードはUTF-8。
フォーマットはCSV:
- 必ずダブルクォートで閉じられている律儀なCVS。
- ダブルクォート内に改行コードが入ってる。
■各カラム:
例1:リプライ。
例2:公式RT。
例3:URL複数付き
コード (tweetscsv.pl):
使い方:
出力の一部:
下記記事のコードを参考にした:
- [を] PerlによるCSVの読み込みとCSVをTSVに変換するワンライナー[2012-03-09-1]
前述のプログラムを用いてざっくり集計。
例1:よく使う source ランキング。
例2:リプライと公式RTの割合。
例3:よくリプライするユーザランキング。
おまけ:形態素解析して名詞だけカウントしたのち意味のありそうなのだけ取り出したランキング。
※ちなみに1位は「http」。他の20位以内の語は「4」などの数字一文字や「co」などのURLの一部。ゴミ抜き処理してないので。
(↑一番最初の発言は2007年3月24日)
「全ツイート履歴」の詳細は下記の記事を参照されたし:
- 日本の皆さんにも「全ツイート履歴」が使えるようになりました (Twitterブログ)
http://blog.jp.twitter.com/2013/03/blog-post_22.html
ダウンロードした中に含まれているファイル「tweets.csv」に全ツイートが入っている。
文字コードはUTF-8。
フォーマットはCSV:
- 必ずダブルクォートで閉じられている律儀なCVS。
- ダブルクォート内に改行コードが入ってる。
■各カラム:
| 0 | tweet_id |
| 1 | in_reply_to_status_id |
| 2 | in_reply_to_user_id |
| 3 | retweeted_status_id |
| 4 | retweeted_status_user_id |
| 5 | timestamp |
| 6 | source |
| 7 | text |
| 8- | expanded_urls |
データ例
例1:リプライ。
(0) 196963653910675456 (1) 196962499604643840 (2) 54396210 (3) - (4) - (5) 2012-04-30 14:06:09 +0000 (6) <a href="http://stone.com/Twittelator" rel="nofollow">Twittelator</a> (7) @TanakaApple ついでに「すぐに家に帰ってしまう区」も考えてください
例2:公式RT。
(0) 196078945374965760 (1) - (2) - (3) 196076541166354432 (4) 5329012 (5) 2012-04-28 03:30:38 +0000 (6) <a href="http://stone.com/Twittelator" rel="nofollow">Twittelator</a> (7) RT @pinkmac: 【速報】夫のこども手当使い込み疑惑が浮上
例3:URL複数付き
(0) 80072148634447873 (1) - (2) - (3) - (4) - (5) 2011-06-13 00:41:02 +0000 (6) <a href="http://twitter.com/tweetbutton" rel="nofollow">Tweet Button</a> (7) 愛知学院大学歯学部付属病院小児科にあるそう http://t.co/Hlfukd6 > 歯医者に置いてあるドラえもんが怖すぎる件... http://t.co/wGeRw9v (8) http://chalow.net/2007-06-25-3.html (9) http://twitpic.com/5aehqd
ざっくり処理するための Perl 雛形
コード (tweetscsv.pl):
#!/usr/bin/perl
use strict;
use warnings;
my $all = join("", <>);
$all =~ s/([^"])\n/$1 /g;
foreach (split(/\n/, $all)) {
my @c = split_csv($_);
print join("\n", map {"($_) $c[$_]"}
grep {$c[$_] ne '"'} 0..$#c)."\n";
}
sub split_csv {
my ($s) = @_;
$s =~ s/""/\x07\x08/g;
my @rv = ("$s," =~ /("[^"]+"|[^,]+|),/g);
return map {s/^"(.*)"$/$1/g; s/\x07\x08/"/g; $_} @rv;
}
使い方:
% ./tweetscsv.pl tweets.csv
出力の一部:
(0) 37441352706826240 (5) 2011-02-15 09:21:28 +0000 (6) <a href="http://tou.ch/" rel="nofollow">ロケタッチ(loctouch)</a> (7) おうちにむかう @ 東京メトロ日比谷線 恵比寿駅にタッチ! http://tou.ch/VOYsCz (0) 37365786729254912 (5) 2011-02-15 04:21:12 +0000 (6) <a href="http://www.hatena.ne.jp/guide/twitter" rel="nofollow">Hatena</a> (7) きのこる先生 / http://f.hatena.ne.... - 2008年の抱負 - yto - はてなハイク http://htn.to/PkN5LY (0) 37365231462264832 (3) 36344413101760512 (4) 207566268 (5) 2011-02-15 04:19:00 +0000 (6) web (7) RT @aknmssm: なんでも文末に「大手メディアはなぜ報じないのだろう?」とつけるといきなり社会派なツイートになる運動を実施しています。この運動をなぜ大手メディアは報じないのか。
下記記事のコードを参考にした:
- [を] PerlによるCSVの読み込みとCSVをTSVに変換するワンライナー[2012-03-09-1]
集計例
前述のプログラムを用いてざっくり集計。
例1:よく使う source ランキング。
| 順位 | 回数 | source |
|---|---|---|
| 1 | 5119 | web |
| 2 | 3828 | twitterfeed |
| 3 | 3582 | Twittelator |
| 4 | 2446 | Flickr |
| 5 | 2066 | Hatena |
| 6 | 970 | movatwitter |
| 7 | 965 | Twittelator |
| 8 | 763 | |
| 9 | 754 | Buffer |
| 10 | 724 | NatsuLiphone |
% ./tweetscsv.pl tweets.csv | grep '^(6)'| cut -c5- | sort | uniq -c | sort -nr | head -20
例2:リプライと公式RTの割合。
| 全ツイート数 | 105959 |
| リプライ率 | 0.016 (1.6%) = 1712/105959 |
| 公式RT率 | 0.013 (1.3%) = 1378/105959 |
% ./tweetscsv.pl tweets.csv | wc -l 105959 % ./tweetscsv.pl tweets.csv | grep '^(3) [1-9]'| wc -l 1712 % ./tweetscsv.pl tweets.csv | grep '^(1) [1-9]'| wc -l 1378
例3:よくリプライするユーザランキング。
| 順位 | 回数 | User ID | ScreenName |
|---|---|---|---|
| 1 | 68 | 10228272 | @YouTube |
| 2 | 67 | 15315186 | @riskyspeeder |
| 3 | 51 | 2067431 | @yto |
| 4 | 48 | 14512408 | @yozora2 |
| 5 | 45 | 16323986 | @mirai2008 |
| 6 | 34 | 2067291 | @kogure |
| 7 | 30 | 7178212 | @wada_akiko |
| 8 | 24 | 5550762 | @yomoyomo |
| 9 | 22 | 14484428 | @makipapa |
| 10 | 21 | 69835788 | @erumoamere |
% ./tweetscsv.pl tweets.csv | grep '^(2) [0-9]'| cut -c5- | sort | uniq -c | sort -nr | head
おまけ:形態素解析して名詞だけカウントしたのち意味のありそうなのだけ取り出したランキング。
| 順位 | 頻度 | 単語(名詞) |
|---|---|---|
| 18 | 1038 | とら |
| 25 | 827 | 恵比寿 |
| 26 | 769 | iPhone |
| 28 | 688 | ブログ |
| 42 | 372 | 発言小町 |
| 43 | 371 | 妻 |
| 45 | 364 | 私 |
| 48 | 345 | 朝 |
| 49 | 342 | 東京 |
この記事に言及しているこのブログ内の記事